Видео ютуба по тегу nvidia inference server

Deploying an Object Detection Model with Nvidia Triton Inference Server

Nvidia Triton Inference Server L08| MLOps 24s | girafe-ai
![[Português] explicAI: Servidor de Inferência NVIDIA Triton para IA [Temporada #2 - Ep. 07]](https://imager.clipsaver.ru/ucweWjUBCZY/max.jpg)
[Português] explicAI: Servidor de Inferência NVIDIA Triton para IA [Temporada #2 - Ep. 07]

VMware Private AI Foundation with NVIDIA Technical Overview and Demo

Triton Inference Server. Part 1. Introduction

NVIDIA H200 GPU Server: The Future of AI Training & Inference Starts Here

GPU-Accelerated LLM Inference on AWS EKS: A Hands-On Guide
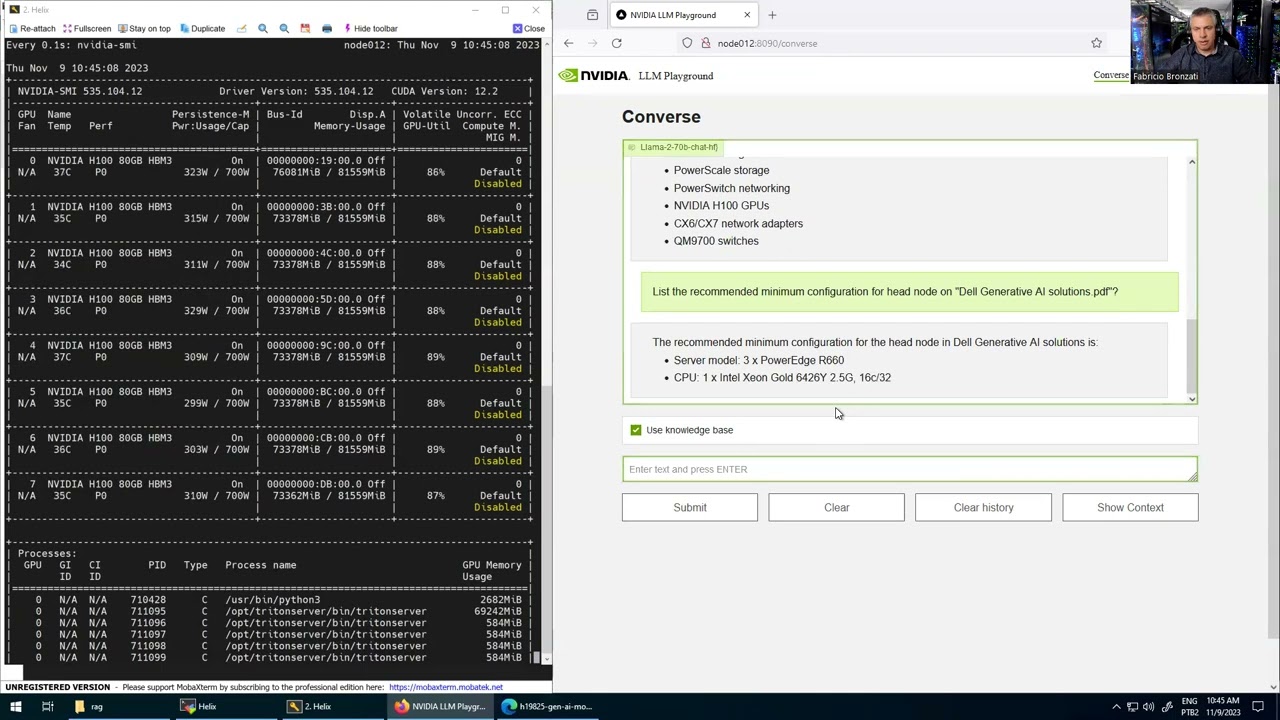
Nvidia LLM Playground Demo

Building GenAI Infrastructure: 5 Key Features of NVIDIA NIM

🚀 Triton Inference Server: Scalable AI Model Deployment

🔍 AI Serving Frameworks Explained: vLLM vs TensorRT-LLM vs Ray Serve | Which One Should You Use?

Bot Pao - Thai ChatBot using Nvidia Triton Inference Server
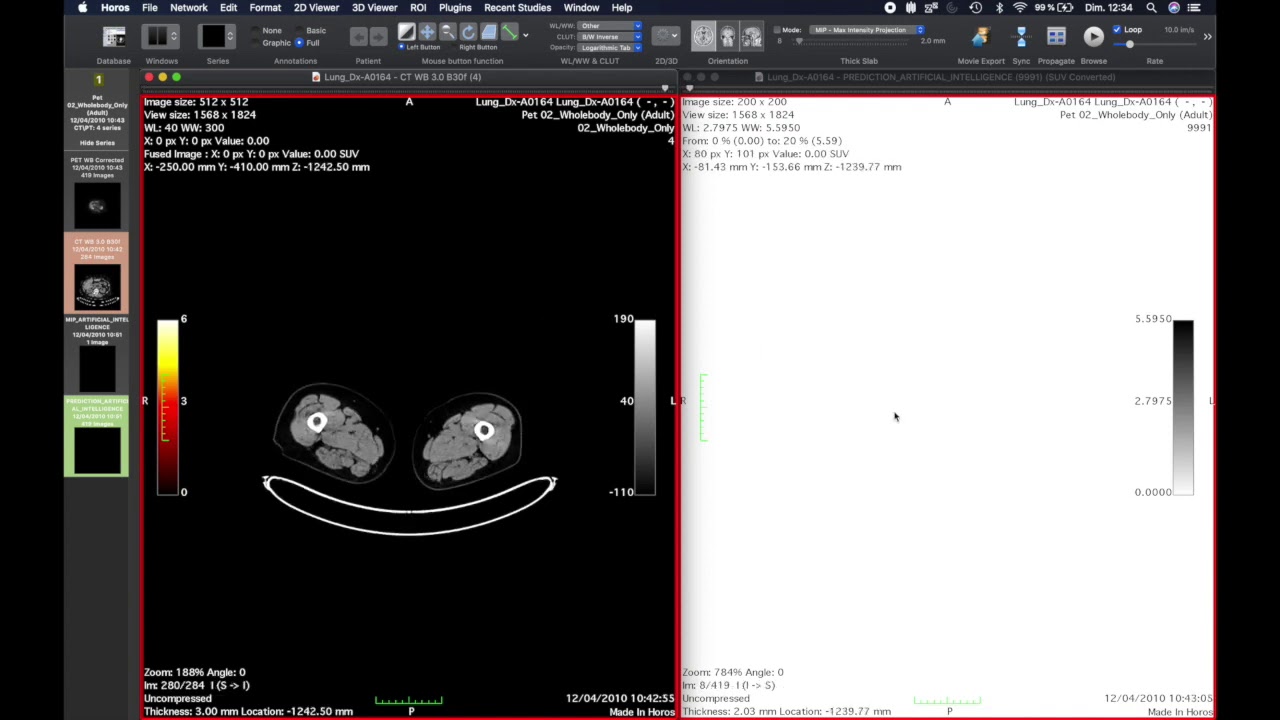
Inference of a PET detection model using the Jetson Nano (NVIDIA) and Horos

A Practical Guide To Benchmarking AI and GPU Workloads in Kubernetes - Yuan Chen & Chen Wang

Accelerate your AI journey: Introducing Red Hat AI Inference Server

Accelerating Edge AI: Optimizing Computer Vision Inference with NVIDIA | YV24 Talk #08 | Ultralytics

AWS On Air ft. Multi Model Endpoints for GPU | AWS Events

Deploy Complex ML Workflows with Triton Inference Server Ensembles

NVIDIA Triton meets ArangoDB Workshop